How a 12 MB Model Picks the Right Vector Index for IoT Workloads
May 16, 2026 · ✎ acmbluffdaleadmin2

A walkthrough of recently published research on adaptive index selection in vector databases, evaluated across four benchmark datasets and a large-scale simulation study.
When the Wrong Index Costs Millions
A retailer lost $340,000 during a Black Friday rush when its similarity-search service ran out of memory mid-checkout. A manufacturer absorbed a $2.1 million hit because its anomaly-detection pipeline missed defects. Recall was too low for the workload it was actually serving. Different industries, different failure modes, same underlying cause. Somebody picked the wrong vector index.
Vector databases now power a remarkable amount of critical infrastructure: smart-city sensor search, industrial monitoring, real-time product retrieval, retrieval-augmented LLMs. The choice of index structure is the single biggest lever determining whether such a system stays up under load. Today, that lever gets pulled by a human expert. Once. Often months before the workload it will actually face.
That does not scale. The two failures above are what it looks like when it breaks.

Three Indexes, Three Trade-offs
Vector indexes are not interchangeable. Each makes different compromises.
- HNSW (Hierarchical Navigable Small World) is graph-based. It delivers excellent recall and low latency, but its memory footprint can be several times the raw vector size. That is dangerous when memory budgets are tight.
- IVF-FLAT (Inverted File with Flat encoding) partitions vectors into clusters and scans only a subset at query time. It uses far less memory, but recall is sensitive to tuning and to distribution shift.
- Hybrid schemes combine partitioning with in-partition graph search, trying to balance the two, at the cost of more configuration surface.
Pick HNSW for a memory-constrained edge gateway and you may exhaust RAM under a query spike. Pick IVF-FLAT for an anomaly-detection workload that needs near-perfect recall on rare patterns and you may miss the very events you deployed the system to catch. Either choice can be defensible at design time and catastrophic at 3 a.m. on Black Friday.
The deeper issue is that workloads are not stationary. Query rates shift with diurnal patterns. New sensors come online and change the data distribution. Batch sizes vary as upstream services adapt. A static choice, however expertly made, is a snapshot of a moving target.
Let the System Pick Its Own Index
AdaptIndex is built on a straightforward premise. If a human expert can pick the right index after inspecting a system’s workload, a model trained on enough of those decisions can too. And it can keep picking, continuously, as the workload evolves.
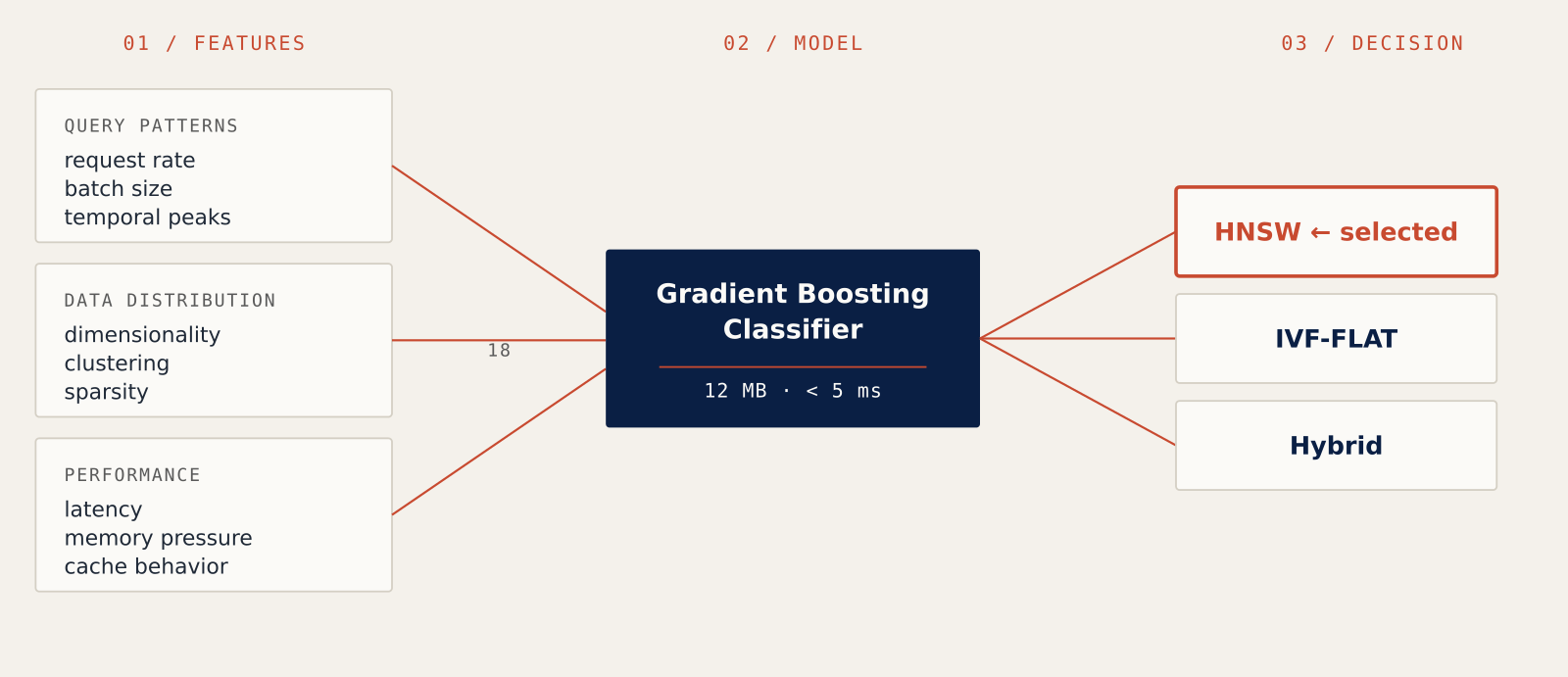
The system extracts 18 features across three families that, together, describe the state of any vector-search deployment:
- Query-pattern features: request rate, batch size, temporal peaks, and other indicators of how the system is being used.
- Data-distribution features: dimensionality, clustering structure, sparsity, and other characteristics of the indexed corpus itself.
- Performance-signal features: observed latency, memory pressure, cache behavior, and other runtime telemetry that reflects how the current configuration is coping.
A gradient-boosting classifier maps that feature vector to a recommended index configuration. Gradient boosting was deliberate. It trains on modest data, runs fast at inference, and surfaces feature importances that a human operator can actually interpret when the system reconfigures itself.
The design constraints were aggressive on purpose:
- Fit on edge hardware. The model is 12 MB on disk.
- Decide fast enough not to become the bottleneck. Inference runs in under 5 milliseconds.
- Generalize across workloads not seen during training.
Those three constraints rule out a lot of fashionable ML choices. They turned out not to be limiting in practice.
Benchmarks
We evaluated AdaptIndex on four datasets:
- SIFT1M and GIST1M, standard ANN benchmarks that let other researchers reproduce results.
- Synthetic-IoT, a synthetic workload designed to model IoT query patterns.
- Production-Edge, an edge-deployment trace.
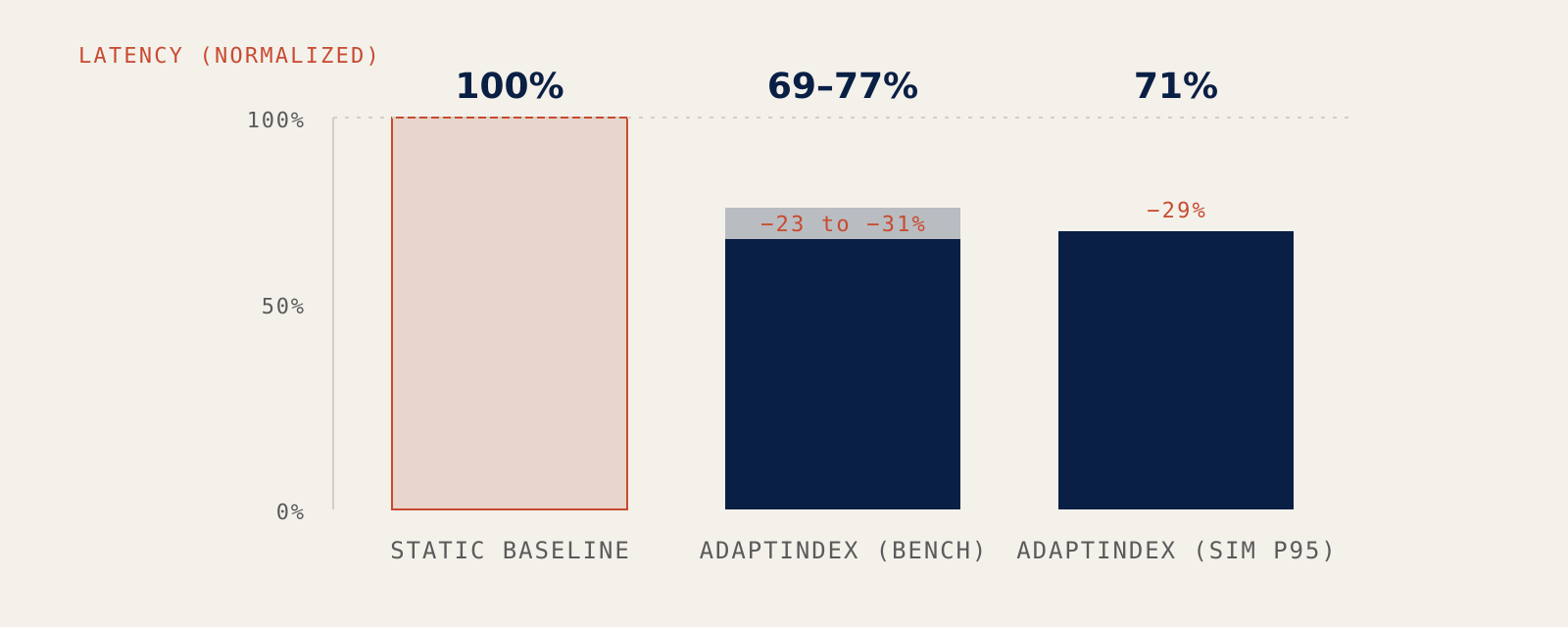
Against the best static configuration on each dataset, AdaptIndex delivered 23 to 31 percent latency improvement, with 89 percent prediction accuracy on the correct index choice. The accuracy number is worth pausing on. Even when the model picked a sub-optimal index, the cost of being wrong was generally small, because the second-best choice in any given regime is rarely catastrophic. The catastrophic choices are the ones the model learns to avoid first.
A Larger Simulation Study
Benchmarks on small datasets are necessary but not sufficient. To test how AdaptIndex behaves under realistic deployment variation, we ran a larger simulation study.
The simulation modeled 47 edge gateways across 12 geographic regions, processing roughly 5 million queries per day for 90 simulated days. The setup intentionally varied hardware profiles, network conditions, and workload mix so the results would not be artifacts of a single configuration.
The paper includes the full simulation breakdown, region by region and workload by workload, for readers who want to see where the model worked best and where it had the most to learn.
What We Take Away
Two things stand out.
For practitioners
If you operate a vector database under any kind of variable workload (and “variable” describes essentially every IoT and recommendation use case), the cost of a static index choice quietly accumulates. AdaptIndex shows that a deployable, lightweight system can recover most of that cost without an expert in the loop and without a heavyweight ML pipeline shadowing your query path.
For the field
A small model with good features can beat a large model with poor ones, even in systems work where ML is often viewed with skepticism. A 12 MB and 5 ms envelope is small enough that the deployment conversation is short. That envelope is itself a contribution. We hope it encourages others to treat “lightweight enough to ship at the edge” as a first-class design constraint, not an afterthought.
Get the full details
The paper covers everything not in this post: full feature definitions, training procedure, dataset construction, model-selection rationale, ablation studies, and the detailed simulation setup that did not fit into an abstract.
By Chandrashekhar M, Vice Chair. Written for the Bluffdale ACM Chapter Blog. Have a topic you’d like to write about? Reach out to us at bluffdale.acm.org/contact.